How to use Redis for real-time stream processing
Real-time streaming data ingest is a common requirement for many big data use cases. In fields like IoT, e-commerce, security, communications, entertainment, finance, and retail, where so much depends on timely and accurate data-driven decision making, real-time data collection and analysis are in fact core to the business.
However, collecting, storing and processing streaming data in large volumes and at high velocity presents architectural challenges. An important first step in delivering real-time data analysis is ensuring that adequate network, compute, storage, and memory resources are available to capture fast data streams. But a company’s software stack must match the performance of its physical infrastructure. Otherwise, businesses will face a massive backlog of data, or worse, missing or incomplete data.
Redis has become a popular choice for such fast data ingest scenarios. A lightweight in-memory database platform, Redis achieves throughput in the millions of operations per second with sub-millisecond latencies, while drawing on minimal resources. It also offers simple implementations, enabled by its multiple data structures and functions.
In this article, I will show how Redis Enterprise can solve common challenges associated with the ingestion and processing of large volumes of high velocity data. We’ll walk through three different approaches (including code) to processing a Twitter feed in real time, using Redis Pub/Sub, Redis Lists, and Redis Sorted Sets, respectively. As we’ll see, all three methods have a role to play in fast data ingestion, depending on the use case.
Challenges in designing fast data ingest solutions
High-speed data ingestion often involves several different types of complexity:
- Large volumes of data sometimes arriving in bursts. Bursty data requires a solution that is capable of processing large volumes of data with minimal latency. Ideally, it should be able to perform millions of writes per second with sub-millisecond latency, using minimal resources.
- Data from multiple sources. Data ingest solutions must be flexible enough to handle data in many different formats, retaining source identity if needed and transforming or normalizing in real-time.
- Data that needs to be filtered, analyzed, or forwarded. Most data ingest solutions have one or more subscribers who consume the data. These are often different applications that function in the same or different locations with a varied set of assumptions. In such cases, the database not only needs to transform the data, but also filter or aggregate depending on the requirements of the consuming applications.
- Data coming from geographically distributed sources. In this scenario, it is often convenient to distribute the data collection nodes, placing them close to the sources. The nodes themselves become part of the fast data ingest solution, to collect, process, forward, or reroute ingest data.
Handling fast data ingest in Redis
Many solutions supporting fast data ingest today are complex, feature-rich, and over-engineered for simple requirements. Redis, on the other hand, is extremely lightweight, fast, and easy to use. With clients available in more than 60 languages, Redis can be easily integrated with the popular software stacks.
Redis offers data structures such as Lists, Sets, Sorted Sets, and Hashes that offer simple and versatile data processing. Redis delivers more than a million read/write operations per second, with sub-millisecond latency on a modestly sized commodity cloud instance, making it extremely resource-efficient for large volumes of data. Redis also supports messaging services and client libraries in all of the popular programming languages, making it well-suited for combining high-speed data ingest and real-time analytics. Redis Pub/Sub commands allow it to play the role of a message broker between publishers and subscribers, a feature often used to send notifications or messages between distributed data ingest nodes.
Redis Enterprise enhances Redis with seamless scaling, always-on availability, automated deployment, and the ability to use cost-effective flash memory as a RAM extender so that the processing of large datasets can be accomplished cost-effectively.
In the sections below, I will outline how to use Redis Enterprise to address common data ingest challenges.
Redis at the speed of Twitter
To illustrate the simplicity of Redis, we’ll explore a sample fast data ingest solution that gathers messages from a Twitter feed. The goal of this solution is to process tweets in real-time and push them down the pipe as they are processed.
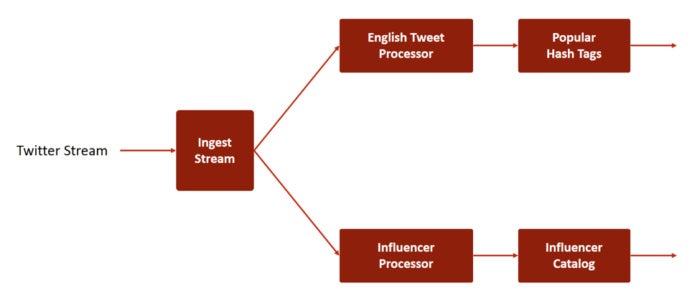
Twitter data ingested by the solution is then consumed by multiple processors down the line. As shown in Figure 1, this example deals with two processors – the English Tweet Processor and the Influencer Processor. Each processor filters the tweets and passes them down its respective channels to other consumers. This chain can go as far as the solution requires. However, in our example, we stop at the third level, where we aggregate popular discussions among English speakers and top influencers.
 Redis Labs
Redis Labs
Figure 1. Flow of the Twitter stream
Note that we are using the example of processing Twitter feeds because of the velocity of data arrival and simplicity. Note also that Twitter data reaches our fast data ingest via a single channel. In many cases, such as IoT, there could be multiple data sources sending data to the main receiver.
There are three possible ways to implement this solution using Redis: ingest with Redis Pub/Sub, ingest with the List data structure, or ingest with the Sorted Set data structure. Let’s examine each of these options.
Ingest with Redis Pub/Sub
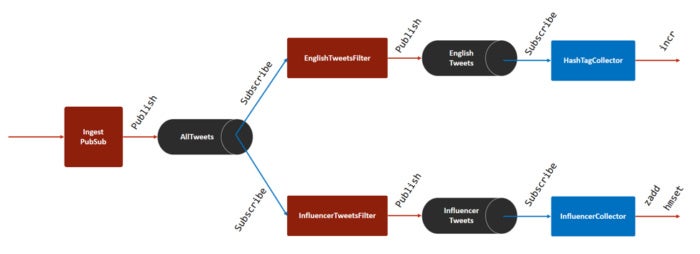
This is the simplest implementation of fast data ingest. This solution uses Redis’s Pub/Sub feature, which allows applications to publish and subscribe to messages. As shown in Figure 2, each stage processes the data and publishes it to a channel. The subsequent stage subscribes to the channel and receives the messages for further processing or filtering.
 Redis Labs
Redis Labs
Figure 2. Data ingest using Redis Pub/Sub
Pros
- Easy to implement.
- Works well when the data sources and processors are distributed geographically.
Cons
- The solution requires the publishers and subscribers to be up all the time. Subscribers lose data when stopped, or when the connection is lost.
- It requires more connections. A program cannot publish and subscribe to the same connection, so each intermediate data processor requires two connections – one to subscribe and one to publish. If running Redis on a DBaaS platform, it is important to verify whether your package or level of service has any limits to the number of connections.
A note about connections
If more than one client subscribes to a channel, Redis pushes the data to each client linearly, one after the other. Large data payloads and many connections may introduce latency between a publisher and its subscribers. Although the default hard limit for maximum number of connections is 10,000, you must test and benchmark how many connections are appropriate for your payload.
Redis maintains a client output buffer for each client. The default limits for the client output buffer for Pub/Sub are set as:
client-output-buffer-limit pubsub 32mb 8mb 60
With this setting, Redis will force clients to disconnect under two conditions: if the output buffer grows beyond 32MB, or if the output buffer holds 8MB of data consistently for 60 seconds.
These are indications that clients are consuming the data more slowly than it is published. Should such a situation arise, first try optimizing the consumers such that they do not add latency while consuming the data. If you notice that your clients are still getting disconnected, then you may increase the limits for the client-output-buffer-limit pubsub property in redis.conf. Please keep in mind that any changes to the settings may increase latency between the publisher and subscriber. Any changes must be tested and verified thoroughly.
Code design for the Redis Pub/Sub solution
 Redis Labs
Redis Labs
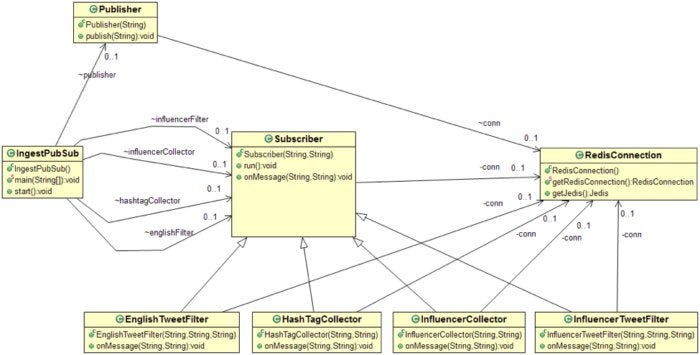
Figure 3. Class diagram of the fast data ingest solution with Redis Pub/Sub
This is the simplest of the three solutions described in this paper. Here are the important Java classes implemented for this solution. Download the source code with full implementation here: https://github.com/redislabsdemo/IngestPubSub.
The Subscriber class is the core class of this design. Every Subscriber object maintains a new connection with Redis.
class Subscriber extends JedisPubSub implements Runnable{
private String name ="Subscriber";
private RedisConnection conn = null;
private Jedis jedis = null;private String subscriberChannel ="defaultchannel";
public Subscriber(String subscriberName, String channelName) throws Exception{
name = subscriberName;
subscriberChannel = channelName;
Thread t = new Thread(this);
t.start();
}
@Override
public void run(){
try{
conn = RedisConnection.getRedisConnection();
jedis = conn.getJedis();
while(true){
jedis.subscribe(this, this.subscriberChannel);
}
}catch(Exception e){
e.printStackTrace();
}
}
@Override
public void onMessage(String channel, String message){
super.onMessage(channel, message);
}
}
The Publisher class maintains a separate connection to Redis for publishing messages to a channel.
public class Publisher{RedisConnection conn = null;
Jedis jedis = null;
private String channel ="defaultchannel";
public Publisher(String channelName) throws Exception{
channel = channelName;
conn = RedisConnection.getRedisConnection();
jedis = conn.getJedis();
}
public void publish(String msg) throws Exception{
jedis.publish(channel, msg);
}
}
The EnglishTweetFilter, InfluencerTweetFilter, HashTagCollector, and InfluencerCollector filters extend Subscriber, which enables them to listen to the inbound channels. Since you need separate Redis connections for subscribe and publish, each filter class has its own RedisConnection object. Filters listen to the new messages in their channels in a loop. Here is the sample code of the EnglishTweetFilter class:
public class EnglishTweetFilter extends Subscriber
{private RedisConnection conn = null;
private Jedis jedis = null;
private String publisherChannel = null;
public EnglishTweetFilter(String name, String subscriberChannel, String publisherChannel) throws Exception{
super(name, subscriberChannel);
this.publisherChannel = publisherChannel;
conn = RedisConnection.getRedisConnection();
jedis = conn.getJedis();
}
@Override
public void onMessage(String subscriberChannel, String message){
JsonParser jsonParser = new JsonParser();
JsonElement jsonElement = jsonParser.parse(message);
JsonObject jsonObject = jsonElement.getAsJsonObject();
//filter messages: publish only English tweets
if(jsonObject.get(“lang”) != null &&
jsonObject.get(“lang”).getAsString().equals(“en”)){
jedis.publish(publisherChannel, message);
}
}
}
The Publisher class has a publish method that publishes messages to the required channel.
public class Publisher{
.
.
public void publish(String msg) throws Exception{
jedis.publish(channel, msg);
}
.
}
The main class reads data from the ingest stream and posts it to the AllData channel. The main method of this class starts all of the filter objects.
public class IngestPubSub
{
.
public void start() throws Exception{
.
.
publisher = new Publisher(“AllData”);englishFilter = new EnglishTweetFilter(“English Filter”,”AllData”,
“EnglishTweets”);
influencerFilter = new InfluencerTweetFilter(“Influencer Filter”,
“AllData”, “InfluencerTweets”);
hashtagCollector = new HashTagCollector(“Hashtag Collector”,
“EnglishTweets”);
influencerCollector = new InfluencerCollector(“Influencer Collector”,
“InfluencerTweets”);
.
.
}
Ingest with Redis Lists
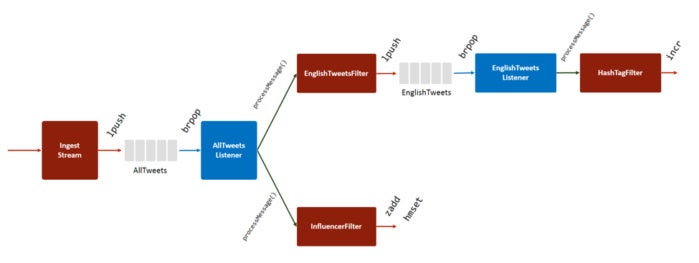
The List data structure in Redis makes implementing a queueing solution easy and straightforward. In this solution, the producer pushes every message to the back of the queue, and the subscriber polls the queue and pulls new messages from the other end.
 Redis Labs
Redis Labs
Figure 4. Fast data ingest with Redis Lists
Pros
- This method is reliable in cases of connection loss. Once data is pushed into the lists, it is preserved there until the subscribers read it. This is true even if the subscribers are stopped or lose their connection with the Redis server.
- Producers and consumers require no connection between them.
Cons
- Once data is pulled from the list, it is removed and cannot be retrieved again. Unless the consumers persist the data, it is lost as soon as it is consumed.
- Every consumer requires a separate queue, which requires storing multiple copies of the data.
Code design for the Redis Lists solution
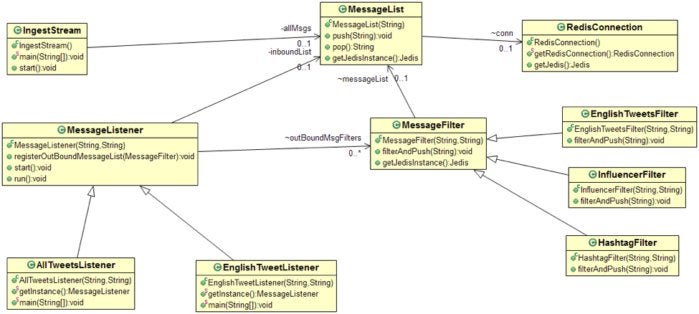 Redis Labs
Redis Labs
Figure 5. Class diagram of the fast data ingest solution with Redis Lists
You can download the source code for the Redis Lists solution here: https://github.com/redislabsdemo/IngestList. This solution’s main classes are explained below.
MessageList embeds the Redis List data structure. The push() method pushes the new message to the left of the queue, and pop() waits for a new message from the right if the queue is empty.
public class MessageList{protected String name = “MyList”; // Name
.
.
public void push(String msg) throws Exception{
jedis.lpush(name, msg); // Left Push
}
public String pop() throws Exception{
return jedis.brpop(0, name).toString();
}
.
.
}
MessageListener is an abstract class that implements listener and publisher logic. A MessageListener object listens to only one list, but can publish to multiple channels (MessageFilter objects). This solution requires a separate MessageFilter object for each subscriber down the pipe.
class MessageListener implements Runnable{
private String name = null;
private MessageList inboundList = null;
Map<String, MessageFilter> outBoundMsgFilters = new HashMap<String, MessageFilter>();
.
.
public void registerOutBoundMessageList(MessageFilter msgFilter){
if(msgFilter != null){
if(outBoundMsgFilters.get(msgFilter.name) == null){
outBoundMsgFilters.put(msgFilter.name, msgFilter);
}
}
}.
.
@Override
public void run(){
.
while(true){
String msg = inboundList.pop();
processMessage(msg);
}
.
}
.
protected void pushMessage(String msg) throws Exception{
Set<String> outBoundMsgNames = outBoundMsgFilters.keySet();
for(String name : outBoundMsgNames ){
MessageFilter msgList = outBoundMsgFilters.get(name);
msgList.filterAndPush(msg);
}
}
}
MessageFilter is a parent class facilitating the filterAndPush() method. As data flows through the ingest system, it is often filtered or transformed before being sent to the next stage. Classes that extend the MessageFilter class override the filterAndPush() method, and implement their own logic to push the filtered message to the next list.
public class MessageFilter{MessageList messageList = null;
.
.
public void filterAndPush(String msg) throws Exception{
messageList.push(msg);
}
.
.
}
AllTweetsListener is a sample implementation of a MessageListener class. This listens to all tweets on the AllData channel, and publishes the data to EnglishTweetsFilter and InfluencerFilter.
public class AllTweetsListener extends MessageListener{
.
.
public static void main(String[] args) throws Exception{
MessageListener allTweetsProcessor = AllTweetsListener.getInstance();allTweetsProcessor.registerOutBoundMessageList(new
EnglishTweetsFilter(“EnglishTweetsFilter”, “EnglishTweets”));
allTweetsProcessor.registerOutBoundMessageList(new
InfluencerFilter(“InfluencerFilter”, “Influencers”));
allTweetsProcessor.start();
}
.
.
}
EnglishTweetsFilter extends MessageFilter. This class implements logic to select only those tweets that are marked as English tweets. The filter discards non-English tweets and pushes English tweets to the next list.
public class EnglishTweetsFilter extends MessageFilter{public EnglishTweetsFilter(String name, String listName) throws Exception{
super(name, listName);
}
@Override
public void filterAndPush(String message) throws Exception{
JsonParser jsonParser = new JsonParser();
JsonElement jsonElement = jsonParser.parse(message);
JsonArray jsonArray = jsonElement.getAsJsonArray();
JsonObject jsonObject = jsonArray.get(1).getAsJsonObject();
if(jsonObject.get(“lang”) != null &&
jsonObject.get(“lang”).getAsString().equals(“en”)){
Jedis jedis = super.getJedisInstance();
if(jedis != null){
jedis.lpush(super.name, jsonObject.toString());
}
}
}
}
Ingest using Redis Sorted Sets
One of the concerns with the Pub/Sub method is that it is susceptible to connection loss and hence unreliable. The challenge with the Redis Lists solution is the problem of data duplication and tight coupling between producers and consumers.
The Redis Sorted Sets solution addresses both of these issues. A counter tracks the number of messages, and the messages are indexed against this message count. They are stored in a non-ephemeral state inside the Sorted Sets data structure, which is polled by consumer applications. The consumers check for new data and pull messages by running the ZRANGEBYSCORE command.
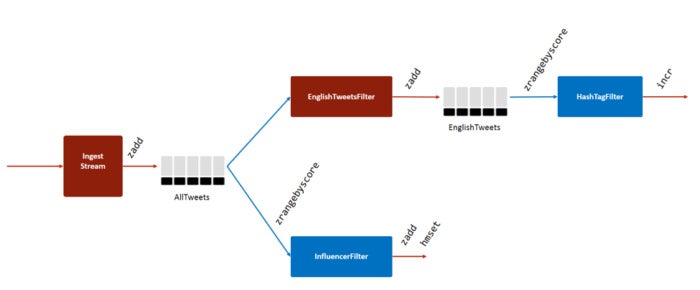 Redis Labs
Redis Labs
Figure 6. Fast data ingest with Redis Sorted Sets and Pub/Sub
Unlike the previous two solutions, this one allows subscribers to retrieve historical data when needed, and consume it more than once. Only one copy of data is stored at each stage, making it ideal for situations where the consumer to producer ratio is very high. However, this approach is more complex and less cost-effective when compared with the last two solutions.
Pros
- It can fetch historical data when needed, because retrieved data is not removed from the Sorted Set.
- The solution is resilient to data connection losses, because producers and consumers require no connection between them.
- Only one copy of data is stored at each stage, making it ideal for situations where the consumer to producer ratio is very high.
Cons
- Implementing the solution is more complex.
- More storage space is required, as data is not deleted from the database when consumed.
Code design for the Redis Sorted Sets solution
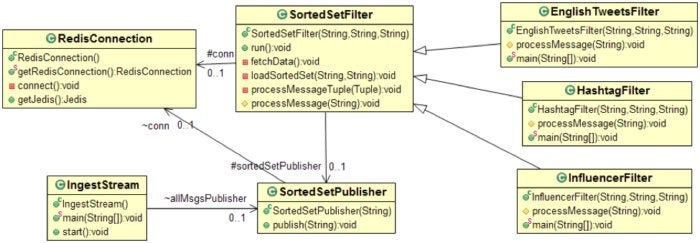 Redis Labs
Redis Labs
Figure 7. Class diagram of the fast data ingest solution with Redis Sorted Sets
You can download the source code here: https://github.com/redislabsdemo/IngestSortedSet. The main classes are explained below.
SortedSetPublisher inserts a message into a Sorted Set and increments the counter that tracks new messages. In many practical cases the counter can be replaced by the timestamp.
public class SortedSetPublisher
{public static String SORTEDSET_COUNT_SUFFIX ="count";
// Redis connection
RedisConnection conn = null;
// Jedis object
Jedis jedis = null;
// name of the Sorted Set data structure
private String sortedSetName = null;
/*
* @param name: SortedSetPublisher constructor
*/
public SortedSetPublisher(String name) throws Exception{
sortedSetName = name;
conn = RedisConnection.getRedisConnection();
jedis = conn.getJedis();
}
/*
*/
public void publish(String message) throws Exception{
// Get count
long count = jedis.incr(sortedSetName+”:”+SORTEDSET_COUNT_SUFFIX);
// Insert into sorted set
jedis.zadd(sortedSetName, (double)count, message);
}
}
The SortedSetFilter class is a parent class that implements logic to learn about new messages, pull them from the database, filter them, and push them to the next level. Classes that implement custom filters extend this class and override the processMessage() method with a custom implementation.
public class SortedSetFilter extends Thread
{
// RedisConnection to query the database
protected RedisConnection conn = null;protected Jedis jedis = null;
protected String name ="SortedSetSubscriber"; // default name
protected String subscriberChannel ="defaultchannel"; //default name
// Name of the Sorted Set
protected String sortedSetName = null;
// Channel (sorted set) to publish
protected String publisherChannel = null;
// The key of the last message processed
protected String lastMsgKey = null;
// The key of the latest message count
protected String currentMsgKey = null;
// Count to store the last message processed
protected volatile String lastMsgCount = null;
// Time-series publisher for the next level
protected SortedSetPublisher SortedSetPublisher = null;
public static String LAST_MESSAGE_COUNT_SUFFIX="lastmessage";
/*
* @param name: name of the SortedSetFilter object
* @param subscriberChannel: name of the channel to listen to the
* availability of new messages
* @param publisherChannel: name of the channel to publish the availability of
* new messages
*/
public SortedSetFilter(String name, String subscriberChannel,
String publisherChannel) throws Exception{
this.name = name;
this.subscriberChannel = subscriberChannel;
this.sortedSetName = subscriberChannel;
this.publisherChannel = publisherChannel;
this.lastMsgKey = name+”:”+LAST_MESSAGE_COUNT_SUFFIX;
this.currentMsgKey =
subscriberChannel+”:”
+SortedSetPublisher.SORTEDSET_COUNT_SUFFIX;
}
@Override
public void run(){
try{
// Connection for reading/writing to sorted sets
conn = RedisConnection.getRedisConnection();
jedis = conn.getJedis();
if(publisherChannel != null){
sortedSetPublisher =
new SortedSetPublisher(publisherChannel);
}
// load delta data since last connection
while(true){
fetchData();
}
}catch(Exception e){
e.printStackTrace();
}
}
/*
* init() method loads the count of the last message processed. It then loads
* all messages since the last count.
*/
private void fetchData() throws Exception{
if(lastMsgCount == null){
lastMsgCount = jedis.get(lastMsgKey);
if(lastMsgCount == null){
lastMsgCount ="0";
}
}
String currentCount = jedis.get(currentMsgKey);
if(currentCount != null && Long.parseLong(currentCount) >
Long.parseLong(lastMsgCount)){
loadSortedSet(lastMsgCount, currentCount);
}else{
Thread.sleep(1000); // sleep for a second if there’s no
// data to fetch
}
}
//Call to load the data from last Count to current Count
private void loadSortedSet(String lastMsgCount, String currentCount)
throws Exception{
//Read from SortedSet
Set<Tuple> CountTuple = jedis.zrangeByScoreWithScores(sortedSetName, lastMsgCount, currentCount);
for(Tuple t : CountTuple){
processMessageTuple(t);
}
}
// Override this method to customize the filters
private void processMessageTuple(Tuple t) throws Exception{
long score = new Double(t.getScore()).longValue();
String message = t.getElement();
lastMsgCount = (new Long(score)).toString();
processMessage(message);
jedis.set(lastMsgKey, lastMsgCount);
}
protected void processMessage(String message) throws Exception{
//Override this method
}
}
EnglishTweetsFilter is a custom filter that extends SortedSetFilter with its own custom filter to select only tweets that are marked as English.
public class EnglishTweetsFilter extends SortedSetFilter
{
/*
* @param name: name of the SortedSetFilter object
* @param subscriberChannel: name of the channel to listen to the
* availability of new messages
* @param publisherChannel: name of the channel to publish the availability
* of new messages
*/
public EnglishTweetsFilter(String name, String subscriberChannel, String publisherChannel) throws Exception{
super(name, subscriberChannel, publisherChannel);
}@Override
protected void processMessage(String message) throws Exception{
//Filter; add them to a new time series database and publish
JsonParser jsonParser = new JsonParser();
JsonElement jsonElement = jsonParser.parse(message);
JsonObject jsonObject = jsonElement.getAsJsonObject();
if(jsonObject.get(“lang”) != null &&
jsonObject.get(“lang”).getAsString().equals(“en”)){
System.out.println(jsonObject.get(“text”).getAsString());
if(sortedSetPublisher != null){
sortedSetPublisher.publish(jsonObject.toString());
}
}
}
/*
* Main method to start EnglishTweetsFilter
*/
public static void main(String[] args) throws Exception{
EnglishTweetsFilter englishFilter = new EnglishTweetsFilter(“EnglishFilter”, “alldata”, “englishtweets”);
englishFilter.start();
}
Final thoughts
When using Redis for fast data ingest, its data structures and pub/sub functionality offer a number of options for implementation. Each approach has its advantages and disadvantages. Redis Pub/Sub is easy to implement, and producers and consumers are decoupled. But Pub/Sub is not resilient to connection loss, and it requires many connections. It’s typically used for e-commerce workflows, job and queue management, social media communications, gaming, and log collection.
The Redis Lists method is also easy to implement, and unlike with Pub/Sub, data is not lost when the subscriber loses the connection. Disadvantages include tight coupling of producers and consumers and the duplication of data for each consumer, which makes it unsuitable for some scenarios. Suitable use cases would include financial transactions, gaming, social media, IoT, and fraud detection.
The Redis Sorted Sets has a larger footprint and is more complex to implement and maintain than the Pub/Sub and List methods, but overcomes their limitations. It is resilient to connection loss, and because retrieved data is not removed from the Sorted Set, it allows for time-series queries. And because only one copy of the data is stored at each stage, it is very efficient in cases where one producer has many consumers. The Sorted Sets method is a good match for IoT transactions, financial transactions, and metering.
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.
Source: InfoWorld Big Data

