
How Arcadia Data brings self-service BI to the data lake
Data has evolved over the years. Complex data structures, unstructured data, real-time processing, growing data volumes, and new varieties of data are all part of the evolution. Platforms have changed as well. “Schema-less,” real-time events, “schema-on-read,” and extract/load/discover/transform (ELDT) are now part of our vernacular.
Despite these changes, many businesses rely on the same data warehouse infrastructure that they’ve relied on for years. Many businesses have also turned to data lakes, through platforms such as Apache Hadoop, NoSQL databases, and Apache Kafka, or cloud storage technologies like Amazon S3, as a cost-effective way of managing large volumes of disparate data sets. Unfortunately, the success rates of these data lakes have been disappointing, as they have not been able to deliver quicker or better value to businesses.
Why isn’t the data lake living up to its promise? It turns out that the data lake architecture is a robust data management strategy, but a weak data intelligence strategy, due to its lack of focus on tools to analyze the data. While the data landscape has evolved, not all tools have kept pace. The data management platforms have changed, and it’s time to rethink the BI and analytics tools as well.
In this article, we’ll examine the advantages of an analytics and BI platform built specifically for data lakes, and how Arcadia Enterprise, the flagship product from Arcadia Data, brings self-service analytics to those environments.
BI and the data lake
A common practice to enable BI on data lakes is to use traditional tools designed for data warehouses and layer them on the data lake. However, because the data in the data lakes is both large in scale and fast moving, what was inefficient but tolerable in the data warehouse has become impractical and even painful in the data lake. Data movement to BI-specific servers, heavy data performance modeling into cubes and extracts, and slow feedback loops between IT and business analysts have all become barriers to insight. BI tools designed for the data warehouse have limited the value of the data lake.
Instead of constraining the value of your data lake, you should embrace a new approach to BI: Keep your existing BI tools for your remaining data warehouse workloads, but use “native” BI tools, i.e., tools that were architected for data lakes, for your modern data platform. These tools are deemed “native” because they run within the data lake cluster—the BI engine is distributed and runs on each data node. Analytics are performed where the data lives, and data movement to a separate BI-specific cluster is eliminated. In addition, the benefits of a native BI platform include unified security, seamless semantic modeling, and query processing optimizations that result in reduced administration, improved self-service, and high speed and scalability.
 Arcadia Data
Arcadia Data
Arcadia Enterprise provides an analytics/BI platform native to big data.
Semantic modeling for self-service BI
If faster time-to-insight on large and diverse data sets is what you hope to achieve from your data lake, then using the right tools will be a key factor in achieving that objective. One key inhibitor to self-service analytics with traditional BI tools is the slow process of moving data from the data lake to the dedicated BI server for analysis. This process has the additional drawback of separating the semantic modeling and analytic/visual discovery steps, resulting in long, drawn-out feedback loops. Arcadia Enterprise shortens the analytics lifecycle by keeping data in the data lake, allowing you to do data discovery and semantic modeling in tighter feedback loops without any IT intervention.
Business analysts need a business-oriented view of the data that they can easily explore and analyze. This “business meaning” needs to be documented alongside the data tables and fields of their database. In Arcadia Enterprise, this information is stored as a “dataset,” a semantic layer that provides a business-facing definition to the underlying data.
The semantic layer is critical for helping non-technical users understand the data. In many traditional analytics environments, semantic layers are created and maintained by IT personnel. This is not an ideal situation, because IT personnel often do not have the same view of data as the analysts. They tend to use different terms, often do not understand the business definition of the data, and often do not know what queries would be run by end users. IT personnel typically need frequent interactions with business analysts to properly define the data.
Arcadia Enterprise provides an easy-to-use interface to let business analysts create and maintain an accurate and detailed semantic layer. Semantic layers can be used to enable the right level of information sharing and collaboration across authorized users. Two key features come into play here:
- Data model definition. Power users or analysts can specify tables (and fields) to join and the join type (e.g., inner, left, right). Users can preview a subset of the joined data.
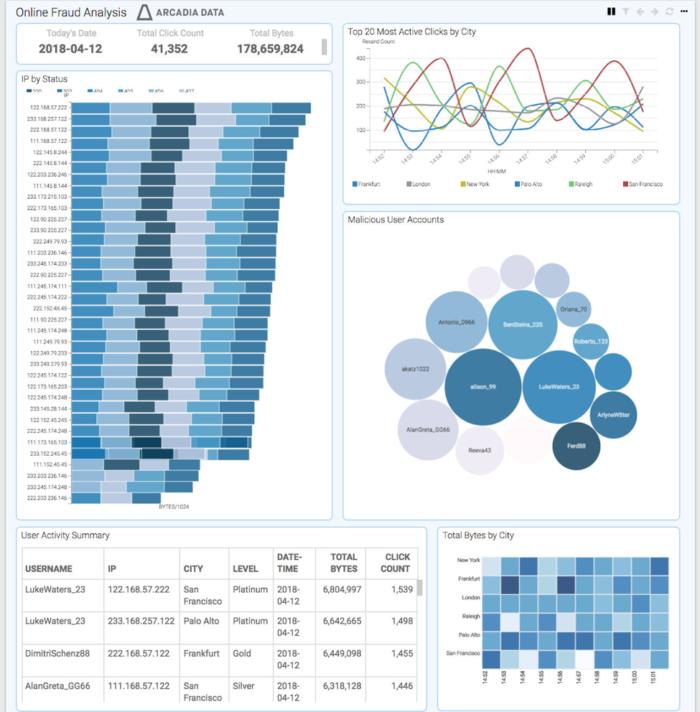
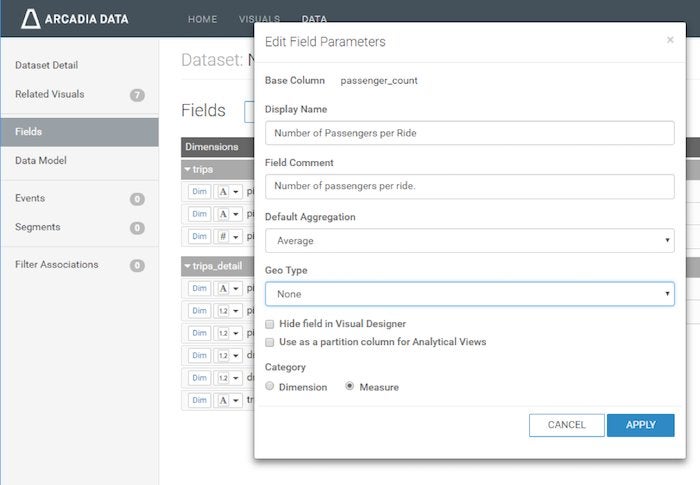
- Field definitions. For enriching information about fields, users can set a display name, add a comment/description, specify a default aggregation (used in the visualization interface), and specify geo type (see screen image below). Users can also categorize fields as a “dimension” or a “measure,” set the data type, and hide fields from the visualization interface.
 Arcadia Data
Arcadia Data
The Arcadia Enterprise semantic layer UI lets users add meaning to data tables.
Arcadia Enterprise initially makes a best guess about field definitions, which can then be updated as desired. As part of a comprehensive self-service analytics platform, the Arcadia Enterprise semantic layer interface simplifies the access to data for non-technical users. Users do not have to turn to IT personnel to define these layers, but are empowered to make adjustments at will and quickly build visualizations, dashboards, and analytical applications.
Accelerating queries with analytical views
Another factor in shorter analytics lifecycles is of course query performance. Here Arcadia Data leverages a technology we call Smart Acceleration, which is a built-in recommendation engine that analyzes queries and defines pre-computed aggregates to speed up application queries with minimal IT effort. These pre-computed aggregates are known as analytical views.
Arcadia Enterprise analytical views are a semantic caching mechanism that allows you to pre-compute and cache the results of expensive SQL operations, such as grouping and aggregation. Query acceleration on data lakes is an increasingly popular topic, especially with new business requirements around high volumes of data and high levels of concurrent users. Businesses are finding that without query acceleration, they can’t fully address the analytical demands of their end users.
But even with query acceleration, using traditional approaches like moving data to a separate, dedicated BI platform is not a sustainable approach. Analytical views represent a unique, native approach to query acceleration in data lakes, providing users with significant performance benefits:
- Queries from apps are automatically routed to analytical views with matching SQL expressions.
- Predictable workloads (querying) can be optimized and completed within a few seconds.
- As the workload becomes more predictable, the automatic use of analytical views increases.
- Analytical views that are well-partitioned (and partitioned identically to the base tables) enable incremental refresh.
The beauty of analytical views is that you don’t need to create and continuously refine your own data cube. Analytical views kick in automatically and can optimize for joins, distinct counts, medians, etc. Since your BI applications are built against the base data, you work with a single unified view of the data with access to all fields, even though specific reports may be supported by different analytical views.
An analytical view gathers and maintains aggregated data based on the query used to create it. Think of it as a shadow to the base tables. It is built using syntax similar to creating a logical view. An analytical view tracks aggregates for columns represented in its query and keeps them updated. Queries using an analytical view gain a significant performance benefit and utilize fewer system resources as compared to running the query against base tables.
When a query is run that can be partially or entirely answered by an analytical view, ArcEngine, the core analytics engine in Arcadia Enterprise, automatically uses that analytical view. The end user of the query is completely unaware of the analytical view. This is helpful because the dashboards that run the queries are built against base tables, not separate data structures, so end users don’t need to think about how best to run their queries.
Here is an example of a base table and an analytical view:
Base table
CREATE EXTERNAL TABLE events
(event_id STRING,
app_id STRING,
app_instance_id STRING,
time TIMESTAMP,
user_id STRING,
device_id STRING,
platform STRING)
PARTITIONED BY (year INT, month INT, day INT);
Analytical view
CREATE ANALYTICAL VIEW events_month_platform_view
PARTITIONED BY (year, month) STORED AS PARQUET AS
(SELECT count(device_id) as count_device_id,
count(user_id) as count_user_id,
month,
platform
FROM events
GROUP BY month, platform);
Refresh the analytical view
REFRESH ANALYTICAL VIEW events_month_platform_view;
In this example, the events table is comprised of data generated by a sensor. This data can have multiple dashboards built on it. An analytical view called events_month_platform_view has been created that tracks the count of users and devices by month and platform. If an analytical view has been outdated due to new or modified data, you can update it incrementally by refreshing it (as long as the partitions of the analytical view are a subset of the partitions of the base table). As you would expect, refreshing incrementally will reduce the time needed to bring the analytical view fully up-to-date.
Defining analytical views starts with the BI developer/analyst understanding which dashboards and underlying queries will be deployed to business users. If you know which queries need acceleration, you can create analytical views manually.
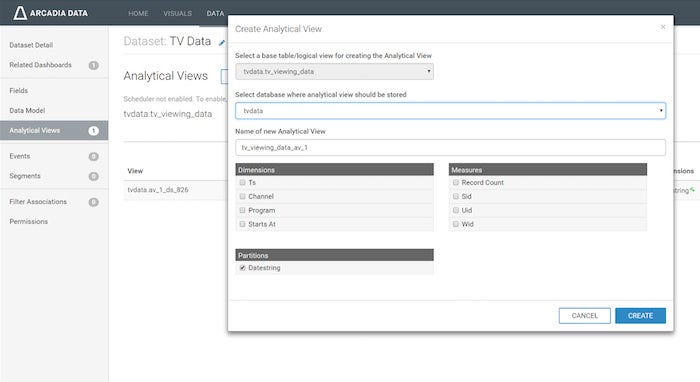
Analytical views can be created manually, or automatically by the system. If you know exactly which queries need acceleration, they can be created manually via the command line as shown in the example above, or by using the Arcadia Enterprise “Create Analytical View” UI as shown in the figure below.
 Arcadia Data
Arcadia Data
The manual option for creating analytical views in the Arcadia Enterprise UI.
However, many times you do not know exactly which queries need to be accelerated, or what is the best combination of analytical views, which is where Smart Acceleration fits in. Smart Acceleration will identify which analytical views to build with its recommendation engine for the dashboards and visuals you select for acceleration.
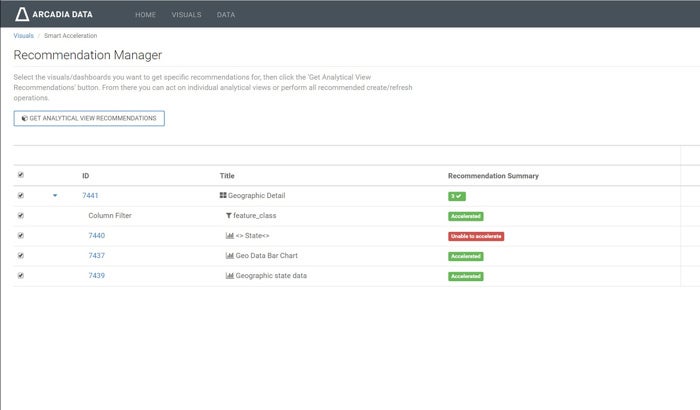
With the Smart Acceleration Recommendation Manager UI (see below), you can select which dashboards or visuals to accelerate, and the system will provide a list of analytical views you can create. The recommended analytical views are defined based on real-world usage of the dashboards, and will identify the most broadly applicable analytical views so that multiple queries can use the same analytical view. This minimizes redundancy across analytical views and guards against system bloat when building views.
 Arcadia Data
Arcadia Data
Arcadia Enterprise’s Smart Acceleration Recommendation Manager simplifies the process of accelerating queries.
If you face long delays in getting data to an analytics-ready state for your business users due to extensive performance modeling, or you aren’t getting the query responsiveness that your end users need, then Arcadia Enterprise analytical views and Smart Acceleration are likely the technologies you need.
Semantic layers and analytical views for modern BI
Business analysts and power users today often have the data knowledge needed to explore data sets and document the business meaning. These users can more accurately design and maintain accurate, business-friendly semantic data layers. To leverage their knowledge and avoid IT bottlenecks, businesses need a platform that empowers non-technical users to create a semantic layer as a precursor to building dashboards, visualizations, and data applications.
Arcadia Enterprise puts discovery and semantic modeling in adjacent tasks to greatly reduce the time to build visualizations. And with Smart Acceleration, Arcadia Enterprise can make recommendations on how to optimize queries with analytical views. The combination of analytical views and Smart Acceleration allows Arcadia Enterprise to support large numbers of concurrent users without the delays of performance modeling that are typical of OLAP cube-oriented environments.
Once analytical views are created, they need to be refreshed as the underlying data gets updated. Refreshes can be run automatically by a scheduler job at regular intervals. Incremental refreshes usually take little time, since they are aggregating data from new or updated partitions.
From this point onward, your dashboards are ready to be operationalized, making the data lake a unified platform for data discovery, as well as a foundation for production analytics applications for use cases spanning 360-degree customer views to cybersecurity, supply chain analysis, and communications network performance optimization.
Priyank Patel is co-founder and chief product officer at Arcadia Data, where he leads the charge in building visually beautiful and highly scalable analytical products. Prior to co-founding Arcadia, he was part of the founding engineering team at Aster Data, where he designed core components of the Aster Database. He later transitioned into field roles to win the company’s first customers in the Eastern US region and then into product management for the SQL-MapReduce and Analytical Frameworks. Following Teradata’s acquisition of Aster, Priyank led product management for its Big Data Appliance in close partnership with Hortonworks.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.
Source: InfoWorld Big Data
