
MapD SQL database gains enterprise-level scale-out, high availability
MapD, the SQL database and analytics platform that uses GPU acceleration for performance orders of magnitude ahead of CPU-based solutions, has been updated to version 3.0.
The update provides a mix of high-end and mundane additions. The high-end goodies consist of deep architectural changes that enable even greater performance gains in clustered environments. But the mundane things are no less important, as they’re aimed at making life easier for enterprise database developers—the audience most likely to use MapD.
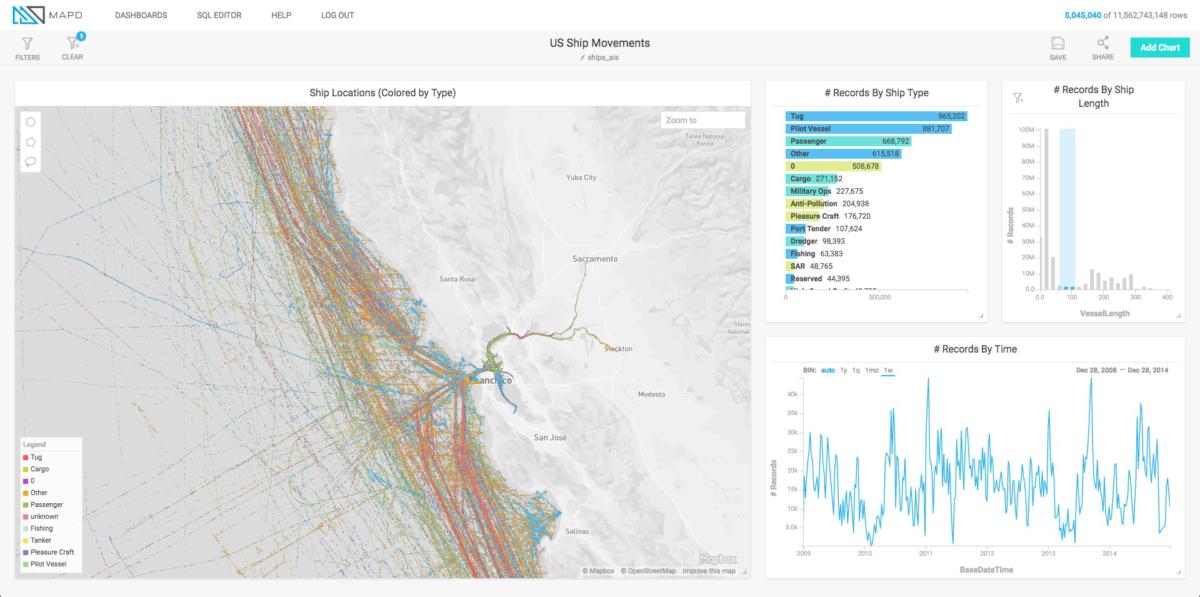
Previous versions of MapD (not to be confused with Hadoop/Spark vendor MapR) were able to scale vertically but not horizontally. Users could add more GPUs to a given box, but they couldn’t scale MapD across multiple GPU-equipped servers. An online demo shows version 3 allowing users to explore in real time an 11-billion-row database of ship movements across the continental U.S. using MapD’s web-based graphical dashboard app.
 IDG
IDG
A live demo of MapD 3.0 running on multiple nodes. An 11-billion-row database of ship movements throughout the continental U.S., can be explored and manipulated in real time, with both the graphical explorer and standard SQL commands.
Version 3 adds a native shared-nothing distributed architecture to the database—a natural extension of the existing shared-nothing architecture MapD used to split processing across GPUs. Data is automatically sharded in round-robin fashion between physical nodes. MapD founder Todd Mostak noted in a phone call that it ought to be possible in the future to manually adjust sharding based on a given database key.
The big advantage to using multiple shared-nothing nodes, according to Mostak, isn’t just a linear speed-up in processing—although that does happen. It also means a linear speed-up for ingesting data into the cluster, which is useful in lowering the bar to entry for database developers who want to try their data out on MapD.
Other features in version 3.0 —chief among them high availability—are what you’d expect from a database aimed at enterprise customers. Nodes can be clustered into HA groups, with data synchronized between them by way of a distributed file system (typically GlusterFS) and a distributed log (by way of an Apache Kafka record stream or “topic”).
Another addition aimed at attracting a general database audience is a native ODBC driver. Third-party tools such as Tableau or Qlik Sense can now plug into MapD without the overhead of the previous JDBC-to-ODBC solution.
A hybrid architecture is one thing that’s not yet possible with MapD’s scale-out system. MapD does have cloud instances available in Amazon Web Services, IBM Soflayer, and Google Cloud, but Mostak pointed out that MapD doesn’t currently support a scenario where nodes in an on-prem installation of MapD can be mixed with nodes from a cloud instance.
Most of MapD’s customers, he explained, have “either-or” setups—either entirely on-prem or entirely in-cloud—with little to no demand to mix the two. At least, not yet.
Source: InfoWorld Big Data