
HBase: The database big data left behind
A few years ago, HBase looked set to become one of the dominant databases in big data. The primary pairing for Hadoop, HBase saw adoption skyrocket, but it has since plateaued, especially compared to NoSQL peers MongoDB, Cassandra, and Redis, as measured by general database popularity.
The question is why.
That is, why has HBase failed to match the popularity of Hadoop, given its pole position with the popular big data platform?
The answer today may be the same offered here on InfoWorld in 2014: It’s too hard. Though I and others expected HBase to rival MongoDB and Cassandra, its narrow utility and inherent complexity have hobbled its popularity and allowed other databases to claim the big data crown.
Popular by association
It started well for HBase. Writing in late 2014, I argued that Hadoop’s preference for HBase, along with its ability to “scale limitlessly as load and performance demands increase simply by adding server nodes,” would keep it as a top-three database for years to come. I was wrong.
According to DB-Engines, which tracks database popularity across a number of metrics (Google searches, job postings, forum mentions), HBase was on a tear for years, keeping pace with the top NoSQL peers. Early in 2015, however, HBase started to slide, even as MongoDB and Cassandra kept rising:
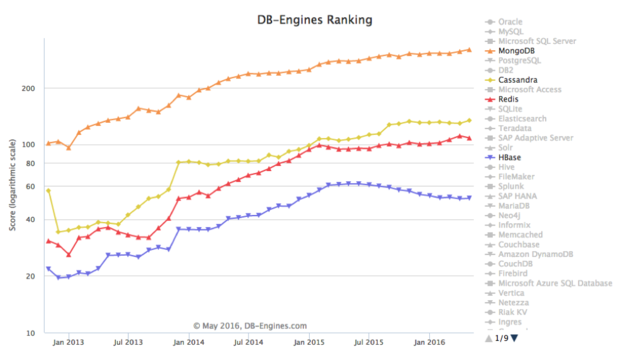
Some argue that DB-Engines’ rankings may undercount an essential popularity metric: how much data is actually stored. By this metric, posits Ewan Leith, “HBase and Cassandra would be in the lead of ‘new’ DBs.”
Perhaps.
But a quick look at Redis, similar to HBase in terms of being a simple data store with limited applicability, suggests something else might be afoot. Redis, after all, started to taper off at about the same time as HBase. The reason for this dual decline is probably tied to the basic workloads both can support, as MongoDB’s Mat Keep told me:

Of course Keep has a bias, but it’s not unfounded. Given that much of MongoDB’s success derives from its ability to support a broad array of operational workloads, Keep is also in a good position to highlight a key failing in HBase.
Though Martin Fowler once declared we had entered the period of “polyglot persistence,” when developers would happily embrace a wide range of tools to tackle a wide range of workloads, reality hasn’t been kind to this “long tail” view of the market.
Ex-Googler (and current Amazon Web Services employee) Tim Bray argues “there is a real cost to this continuous widening of the base of knowledge a developer has to have to remain relevant.” RedMonk analyst Stephen O’Grady takes this a step further: “It could be that we’re approaching the too-much-of-a-good-thing stage. In which case, the logical outcome will be a gradual slowing of fragmentation followed by gradual consolidation.”
In other words, niche data stores that do one thing really well are giving way to more generally applicable databases that can serve a broader range of enterprise needs.
The second part of Keep’s sentence above, however, spells out another reason HBase is struggling: It’s really hard to use.
Making big data hard
Server Density CEO David Mytton, for one, argues that HBase is a “pain to deploy and run.” Another industry insider, who preferred not to be named, was more emphatic, decreeing that HBase is “impossible to run.”
Two years ago InfoWorld’s Rick Grehan pointed to the inherent difficulty in clustering and troubleshooting HBase, not to mention some of the difficulties related to its schema. In 2016, these problems have been addressed with middling success, in large part because simplicity isn’t easily engineered into a product after the fact. This leaves HBase far harder to cluster than Cassandra and far less flexible than MongoDB.
This complexity would be worth wading through if HBase didn’t also have a relatively narrow scope of applicability to “back office (analytics) workloads,” as MongoDB’s Henrik Ingo points out. Indeed, by some estimates, HBase’s only real appeal is scalability and integration with Hadoop, but most people don’t do operational workloads on Hadoop. Even Cloudera’s Justin Kestelyn, an advocate for HBase, admits it has more “specific” use cases than MongoDB and the rest.
As other big data tech has emerged to extend or supersede Hadoop, HBase’s pole position with Hadoop has come to mean less and less, even as the need for general-purpose NoSQL databases has come to matter more and more. By not evolving to embrace a bigger universe of workloads and not making it easier to use HBase, it continues to play a part in NoSQL, but not the dominant one it once could claim.
Source: InfoWorld Big Data