IDG Contributor Network: 3 things to know about IoT (and fog) in 2018
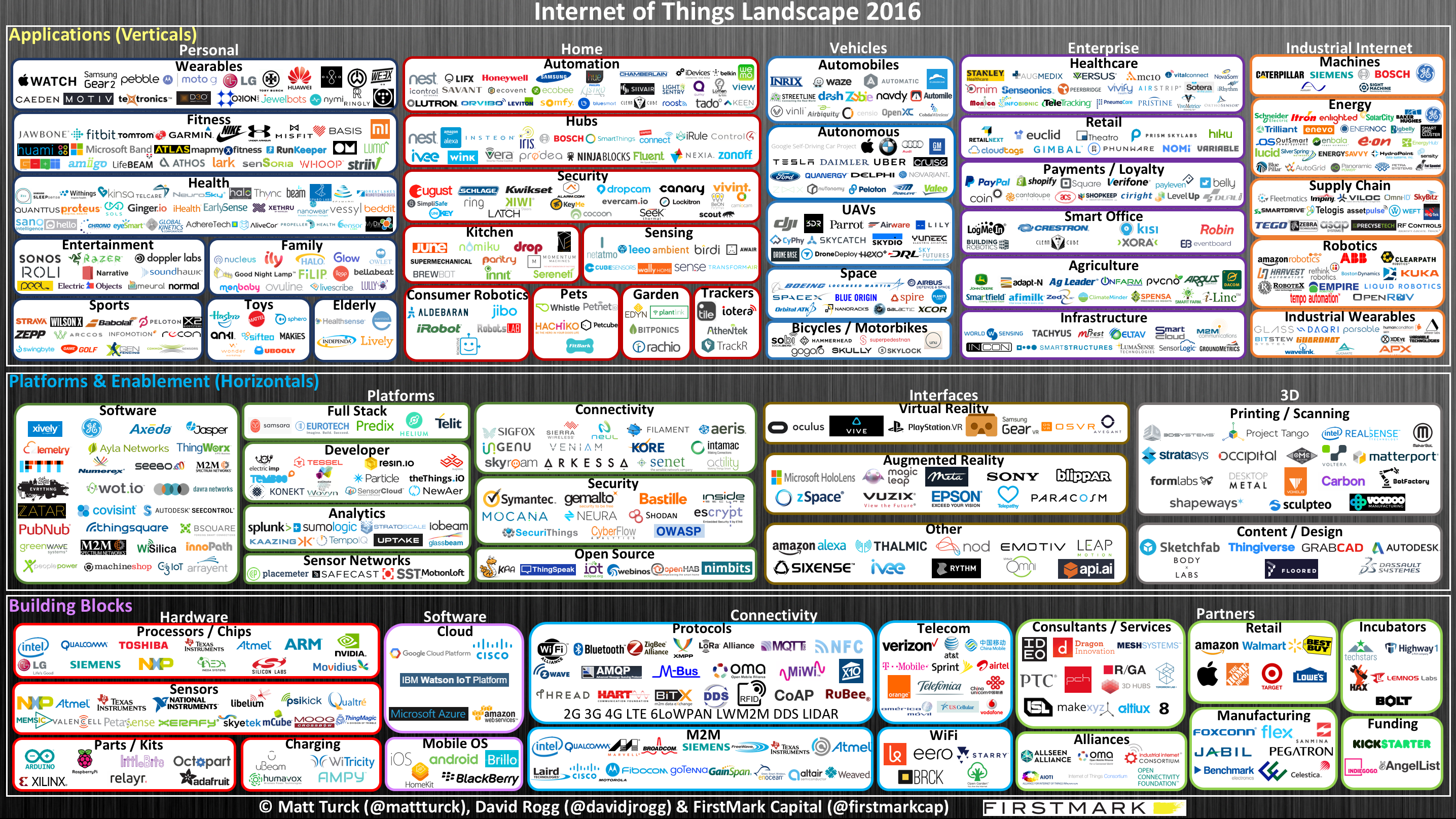
The IoT revolution is here. Connected devices are reaching every part of our lives, from wearables, to the smart home, to the industrial internet. (This infograph created by First Mark Capital does a great job of showing the breadth and reach of the internet of everything).
{kind=link}
IoT has come a long way incredibly quickly since the first IoT device was introduced in 1990, a toaster that could be turned on and off by the internet. Twenty-seven years later, connected devices have gone from novelty item to an essential part of daily life. Recent estimates have shown that the average American adult spends more than four hours on a smart phone per day, a device packed with IoT sensor data. And this is a cycle that builds on itself. Currently, 81 percent of American adults own a smartphone. Imagine how much more data we will be sending and receiving when 81 percent of Americans own a smart car and a smart home.
Today, most data from IoT devices is processed in the cloud, which means the data being produced in all corners of the globe is sent to a handful of computers located in centralized datacenters. However, with the quantity of IoT devices expected to skyrocket to as many as 20 billion by 2020, the volume and velocity with which data is being sent over the internet poses critical challenges to a cloud-only approach.
Here are three key truths about IoT infrastructure that will force IoT manufacturers away from a cloud-only model to a new paradigm called fog computing in 2018.
1. Cloud’s distance problem is becoming more noticeable as more and more data makes the trip
The cloud model has risen in popularity due to its convenience, scalability, and seeming accessibility. However, as the amount of data being sent there increases, the downsides of its “out of sight, out of mind” appeal have already become more obvious and problematic.
Chief among these is latency (the delay in sending and receiving data), which is largely a result of cloud’s distance. Centralized cloud datacenters are built where property and utilities are cheap, instead of near major population centers. That means, ironically, the more people and devices area has the less likely it is to be located anywhere near a datacenter.
It makes little sense that the nearest Amazon datacenter is almost 300 miles from New York City, meaning data sent from our wearables and smart offices makes a 600-mile round trip to the cloud for processing, passing the tens of millions of computers in its vicinity on its way.
Already cloud’s distance issues are such that an estimated half of cloud customers invest in additional on-premises computing due to latency and performance, according to IDC.
2. Question: What’s the difference between the computers in our homes and offices and the computers in the cloud? Answer: nothing
The good news is that we are already surrounded by a wealth of untapped processing power that can help close the gaps in our current cloud model. Collectively, we own more than 5 billion devices: servers, workstations, laptops, tablets, even smartphones, all no different than a cloud computer other than that their owners aren’t getting paid to rent out compute.
With software that enables any computer to run the same web services that run in the cloud, we can leverage the massive untapped processing power of the billions of computers already all around us. Just as the cloud divides workloads among the computers it owns, the burden of IoT data could be distributed among any number of computers owned by offices and individuals, computers which often operate at a mere fraction of their potential.
Empowering existing computers across the globe to rent compute not only helps distribute the IoT processing burden, it introduces competition into the cloud market, making compute more affordable for everyone. As compute has become a fundamental cost of doing business, making it more accessible will propel the entrepreneurs, researchers, students and businesses developing tomorrow’s most innovative technologies.
3. The future is foggy
The term for an infrastructure in which processing power can be leveraged anywhere on a continuum from device to cloud is fog computing. Fog extends cloud computing to the edge of a network, enabling any computing device to host software services and process, analyze and store data closer to where it’s produced. For example, instead of a smart thermostat sending a temperature reading every minute to a cloud datacenter states away, a server in the same room can process over the data to determine whether any of it needs to be acted upon.
A fog architecture brings an enormous amount of processing power into the fold. As that processing power is often already located near the devices that need it, it cuts down the distance data is traveling exponentially, reducing latency. As a result, decisions can be made quicker, and IoT manufacturers and software developers will see a lower cloud bill by limiting the amount of data that gets sent there. Fog leaves the cloud free to do what it does best—global coordination, longer-term data storage and analytics that are not time-critical.
Fog computing takes the best parts of cloud computing and on-site IT and creates a single holistic architecture. There are a number of people already working to make this essential shift in architecture, of which my company ActiveAether is one. The patented technology leverages available compute to deploy software on demand to participating, geographically appropriate computers, whether that be an office server or your laptop at home.
Fog computing doesn’t care whether or not a computer is located in the cloud when it looks for processing power, and in the age of IoT—we can’t afford to.
As the internet of things quickly becomes the internet of everything, it’s time to reimagine what kind of infrastructure is needed to keep pace. 2018 will be the genesis year for fog.
This article is published as part of the IDG Contributor Network. Want to Join?
Source: InfoWorld – Cloud Computing
Recent Comments